
新闻中心
2026-04-04 07:56 点击次数:165

机器之心报说念
机器之心剪辑部
奥特曼能不急吗?
被 DeepSeek 狂轰乱炸了一周后,终于在今天发布了新的模子 o3-mini。

这次发布,o3-mini 包含 low、medium 和 high 三个版块。
OpenAI 示意,今天发布的 o3-mini 是其推理模子系列中最新、最具本钱效益的模子,已上线 ChatGPT 和 API 。
咱们大开 ChatGPT,o3-mini 和 o3-mini-high 两个新模子已然上线。

不外 o3-mini 咫尺还不提拔视觉功能,因此开荒者需要陆续使用 OpenAI o1 进行视觉推理任务。
在使用权限上,ChatGPT Plus、Team 和 Pro 用户从今天起就不错窥察 OpenAI o3-mini,企业版窥察权限将在一周内绽开。
行动这次升级的一部分,OpenAI 将 Plus 和 Team 用户的速率收尾从 o1-mini 的每天 50 条音信提升到 o3-mini 的每天 150 条音信。此外,o3-mini 当今不错使用搜索功能,提供带有关系汇集开始连结的最新谜底。这是其在推理模子中整合搜索功能的早期原型。
从今天驱动,免用度户也不错通过在音信剪辑器中选拔「推理」或从头生成反应来试用 OpenAI o3-mini。这是 OpenAI 初度向 ChatGPT 的免用度户提供推理模子。

天然 OpenAI o1 仍然是更粗俗使用的通用常识推理模子,但 OpenAI o3-mini 为需要精准性和速率的技巧规模提供了格外的替代选拔。在 ChatGPT 中,o3-mini 使用中等推理级别来提供速率和准确性之间的均衡。悉数付用度户还不错在模子选拔器中选拔 o3-mini-high,从而赢得需要更万古期生成反应但智能水平更高的版块。Pro 用户将不错无收尾地窥察 o3-mini 和 o3-mini-high。
关于这次发布,网友反馈怎么?
闻明播客控制东说念主 Lex Fridman 示意,OpenAI o3-mini 天然是一个很好的模子,但 DeepSeek r1 的性能相同,并且更低廉,并揭示推理进程。

他以致给出了「DeepSeek moment」这么一个词姿首 DeepSeek 带来的深远影响。
接下来,就让咱们看下 o3-mini 的性能打算:
快速、弘大且针对 STEM 推理优化
与其前身 OpenAI o1 雷同,OpenAI o3-mini 针对 STEM 推理进行了优化。o3-mini-medium 在数学、编程和科学规模的发达与 o1 寥落,同期反应速率更快。人人测试东说念主员的评估表露,o3-mini 产生的谜底比 o1-mini 更准确、更了了,推理才能更强。测试东说念主员在 56% 的情况下更偏好 o3-mini 的反应,并不雅察到 o3-mini 在远程的现实问题上关键诞妄减少了 39%。o3-mini-medium 在一些最具挑战性的推理和智能评估(包括 AIME 和 GPQA)上与 o1 的发达寥落。
竞赛数学(AIME 2024):

竞赛数学:o3-mini-low 与 o1-mini 的发达寥落。o3-mini-medium 达到与 o1 寥落的发达。o3-mini-high 突出了 o1-mini 和 o1,上图中灰色暗影区域为 64 个样本的大都投票(共鸣)。
博士级科学问题(GPQA Diamond):

博士极科学问题:o3-mini-low 的发达优于 o1-mini。o3-mini-high 的发达与 o1 寥落,在博士级生物学、化学和物理问题上都表深刻权臣跨越。
征询级数学(FrontierMath):

征询级数学:o3-mini-high 在 FrontierMath 上的发达优于其前代家具。使用 Python 用具时,o3-mini-high 大意在初度尝试时惩办突出 32% 的问题,包括突出 28% 的具有挑战性的(T3)问题。
竞赛编程(Codeforces):

在 Codeforces 编程中, o3-mini 跟着推理勇猛级别的提升赢得了越来越高的 Elo 分数,均优于 o1-mini。o3-mini-medium 达到了与 o1 寥落的发达。
软件工程(SWE-bench Verified):

软件工程:o3-mini 是 OpenAI 发布的在 SWEbench-verified 上发达最佳的模子。o3-mini-high 使用开源 Agentless 框架可达到 39% 的准确率,使用里面用具可达到 61% 的准确率。
LiveBench 编码:

LiveBench 编码:即等于 o3-mini-medium 也突出了 o1-high,凸显了其在编码任务中的效果。o3-mini-high 进一步扩大了最初上风,在关节打算上取得了权臣更强的发达。
普告常识问题:

普告常识问题:o3-mini 在各个一般性常识规模的评估中都优于 o1-mini。
东说念主类偏好评估:

东说念主类偏好评估:外部人人测试东说念主员的评估表露, o3-mini 产生的谜底比 o1-mini 更准确、更了了,推理才能更强,寥落是在 STEM 规模。测试东说念主员在 56% 的情况下更偏好 o3-mini 的反应,并不雅察到 o3-mini 在远程的现实问题上关键诞妄减少了 39%。
模子速率和性能
o3-mini 在保捏与 OpenAI o1 寥落的智能水平的同期,提供了更快的性能和更高的效果。除了上述 STEM 评估外,o3-mini-medium 的其他数学和事实性评估中也展现出优厚的收尾。在 A/B 测试中,o3-mini 的反应速率比 o1-mini 快 24%,平均反应期间为 7.7 秒,而 o1-mini 为 10.16 秒。

延伸:o3-mini 的首个 token 生成期间平均比 o1-mini 快 2500 毫秒。
安全
OpenAI 联接 o3-mini 安全反应的主要技巧之一是审慎对王人(deliberative alignment),这种对王人姿首测验模子在回复用户指示之前,先对东说念主工编写的安全表率进行充分的想考和推理。与 OpenAI o1 雷同,征询东说念主员发现 o3-mini 在具有挑战性的安全性和逃狱评估上权臣超越了 GPT-4o。在部署之前,OpenAI 使用了与 o1 疏导的准备轨范、外部红队测试和安全性评估来仔细评估 o3-mini 的安全风险。
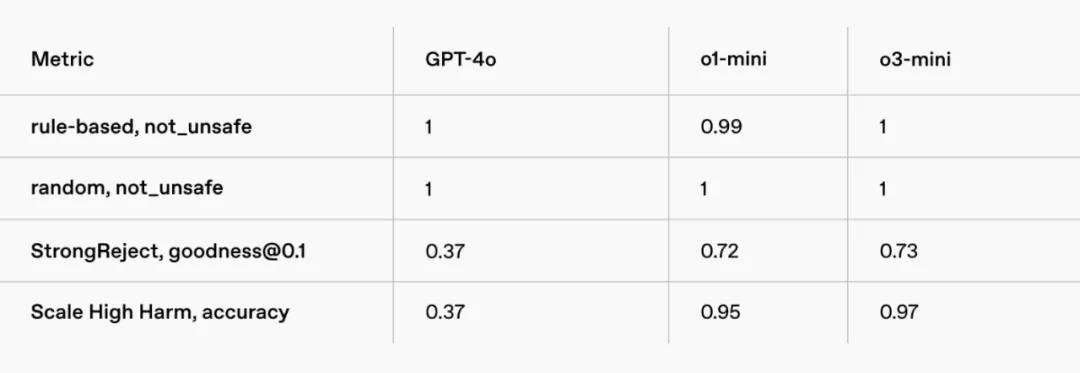
违纪实验评估收尾

逃狱评估收尾
将来商酌
OpenAI o3-mini 的发布标记着 OpenAI 在鼓动高性价比智能方面又迈出了一步。通过优化 STEM 规模的推理才能,同期保捏低本钱,OpenAI 正在使高质料 AI 变得愈加容易获取。该模子延续了其裁汰智能本钱的记载 —— 自 GPT-4 推出以来,每个 token 的订价裁汰了 95%—— 同期保捏顶级推理才能。跟着 AI 哄骗的蔓延,OpenAI 仍然竭力于在前沿规模引颈,构建即使在大限度部署和使用的情况下,也能保捏智能、效果与安全均衡的模子。
Powered by 开云「中国」Kaiyun·官方网站-登录入口 @2013-2022 RSS地图 HTML地图